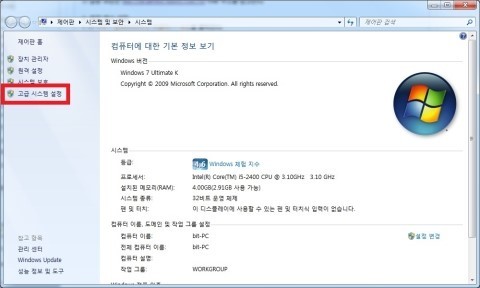
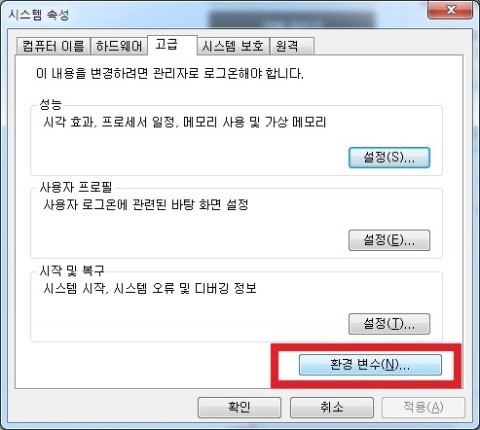
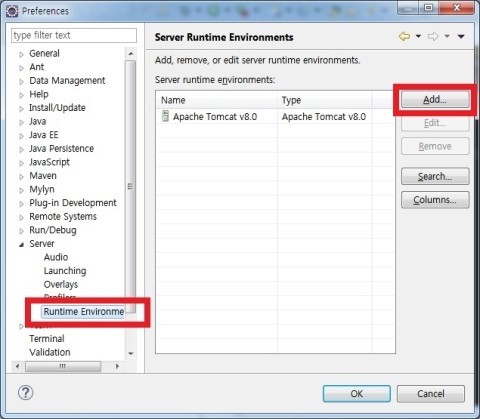
- OS platform : Windows7 Ultimate K
- Develop Tool : Eclipse Luna Java EE IDE, Apache Tomcat 8.0, MySQL Server 5.6
- 구상 : 서블릿으로 MySQL과 연동하여 CRUD 기능을 구현한다.
1. DB 생성
>
CREATE DATABASE [DB_name]
2. Table 생성
>
CREATE TABLE [Table_name]
>
(ID INT NOT NULL AUTO_INCREMENT,
>
name varchar(40),
>
age varchar(40),
>
tel varchar(40),
>
gender varchar(40),
>
addr varchar(40),
>
PRIMARY KEY (ID));
3. 확인하기
▶ Research 기능 추가 : Servlet.GenericServlet을 상속받아서 사용한다.
▶ Create 기능 추가 : Servlet.http.HttpServlet을 상속받아서 사용한다.
▶ Update, Delete 기능 추가
▶ 내부 xml 파일 수정
================================================================
package mobile.mysql;
import java.io.*;
import javax.servlet.*;
import javax.servlet.annotation.WebServlet;
@WebServlet("/mobile.mysql/HomeMobile")
public class HomeMobile extends GenericServlet {
private static final long serialVersionUID = 1911651036498342431L;
public void service(ServletRequest request, ServletResponse response)
throws ServletException, IOException {
request.setCharacterEncoding("UTF-8");
response.setContentType("text/html; charset=UTF-8");
PrintWriter out = response.getWriter();
out.print("<html><head><title>MySQL 테이블 관리</title></head>");
out.print("<body>");
out.print("<div data-role=\"page\" id=\"pageone\">");
out.print("<div data-role=\"main\" class=\"ui-content\">");
out.print("<ul data-role=\"listview\" data-inset=\"true\">");
out.print("<li data-role=\"divider\">MySQL Manager</li>");
out.print("<li><a href=\"ResearchMobile\">테이블 보기</a></li>");
out.print("<li><a href=\"CreateMobile\">테이블 생성</a></li>");
out.print("</ul></div></div></body></html>");
}
}
================================================================
================================================================
package mobile.mysql;
import java.io.*;
import javax.servlet.*;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.*;
import java.sql.*;
@WebServlet("/mobile.mysql/CreateMobile")
public class CreateMobile extends HttpServlet{
private String name;
private String age;
private String tel;
private String gender;
private String addr;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public String getTel() {
return tel;
}
public void setTel(String tel) {
this.tel = tel;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws
ServletException, IOException {
response.setCharacterEncoding("UTF-8");
response.setContentType("text/html; charset=UTF-8");
PrintWriter out = response.getWriter();
out.println("<html>");
out.println("<body><h1>등록하기</h1>");
out.println("<form action='CreateMobile' method='post'>");
out.println("이름: <input type='text' name='Pname'><br>");
out.println("나이: <input type='text' name='Page'><br>");
out.println("전화번호: <input type='text' name='Ptel'><br>");
out.println("성별: <input type='text' name='Pgender'><br>");
out.println("주소: <input type='text' name='Paddr'><br>");
out.println("<input type='submit' value='추가'>");
out.println("<input type='reset' value='초기화'>");
out.println("<input type='reset' value='초기화'>");
out.println("</form>");
out.println("</body></html>");
}
protected void doPost(HttpServletRequest request,
HttpServletResponse response) throws
ServletException, IOException {
request.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
Connection con = null;
PreparedStatement ps = null;
try {
ServletContext sc = this.getServletContext();
Class.forName(sc.getInitParameter("driver"));
con = DriverManager.getConnection(sc.getInitParameter("url"),
"ID", "PASSWORD");
ps = con.prepareStatement("INSERT INTO introduce(name, age,
tel, gender, addr) values(?, ?, ?, ?, ?)");
ps.setString(1, request.getParameter("Pname"));
ps.setString(2, request.getParameter("Page"));
ps.setString(3, request.getParameter("Ptel"));
ps.setString(4, request.getParameter("Pgender"));
ps.setString(5, request.getParameter("Paddr"));
con.setAutoCommit(false);
ps.executeUpdate();
con.commit();
out.print("OK");
response.sendRedirect("ResearchMobile");
} catch (Exception exc) {
out.println("WTF");
try {
con.rollback();
} catch (SQLException e) {
e.printStackTrace();
}
exc.printStackTrace();
}finally{
try {
con.setAutoCommit(true);
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
================================================================
================================================================
package mobile.mysql;
import java.io.*;
import java.sql.*;
import javax.servlet.*;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.*;
@WebServlet("/mobile.mysql/DeleteMobile")
public class DeleteMobile extends HttpServlet {
private static final long serialVersionUID = 6725810624664408130L;
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
response.setContentType("text/html; charset=UTF-8");
Connection con = null;
PreparedStatement ps = null;
String sql = "DELETE FROM introduce WHERE ID=?";
try {
ServletContext sc = this.getServletContext();
Class.forName(sc.getInitParameter("driver"));
con = DriverManager.getConnection(sc.getInitParameter("url"),
"ID", "PASSWORD");
ps = con.prepareStatement(sql);
ps.setInt(1, Integer.parseInt(request.getParameter("ID")));
ps.executeUpdate();
response.sendRedirect("ResearchMobile");
} catch (Exception e) {
throw new ServletException(e);
} finally {
}
}
}
================================================================
================================================================
package mobile.mysql;
import java.io.*;
import java.sql.*;
import javax.servlet.*;
import javax.servlet.annotation.WebServlet;
@WebServlet("/mobile.mysql/ResearchMobile")
public class ResearchMobile extends GenericServlet {
/**
*
*/
private static final long serialVersionUID = -5190955829720826944L;
public void service(ServletRequest request, ServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("UTF-8");
response.setContentType("text/html; charset=UTF-8");
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
PrintWriter out = response.getWriter();
try {
ServletContext sc = this.getServletContext();
Class.forName(sc.getInitParameter("driver"));
con = DriverManager.getConnection(sc.getInitParameter("url"),
"ID", "PASSWORD");
ps = con.prepareStatement("select * from introduce");
rs = ps.executeQuery();
out.print("<html><body>");
out.print("<table>");
out.print("<tr>");
out.print("<td style=\"text-align:center\"> 번호 </td>");
out.print("<td style=\"text-align:center\"> 이름 </td>");
out.print("<td style=\"text-align:center\"> 나이 </td>");
out.print("<td style=\"text-align:center\"> 전화 </td>");
out.print("<td style=\"text-align:center\"> 성별 </td>");
out.print("<td style=\"text-align:center\"> 주소 </td>");
out.print("<td style=\"text-align:center\" colspan=\"2\">
옵션 </td>");
out.print("</tr>");
while (rs.next()) {
out.print("<tr>");
out.print("<td style=\"text-align:center\">" + rs.getInt("ID") +
"</td>");
out.print("<td style=\"text-align:center\">" +
rs.getString("name") + "</td>");
out.print("<td style=\"text-align:center\">" +
rs.getString("age") + "</td>");
out.print("<td style=\"text-align:center\">" +
rs.getString("tel") + "</td>");
out.print("<td style=\"text-align:center\">" +
rs.getString("gender") + "</td>");
out.print("<td style=\"text-align:center\">" +
rs.getString("addr") + "</td>");
out.print("<td style=\"text-align:center\">
<a href='UpdateMobile?ID=" + rs.getInt("ID") + "'>수정</a></td>");
out.print("<td style=\"text-align:center\">
<a href='DeleteMobile?ID=" + rs.getInt("ID") + "'>삭제</a></td>");
out.print("</tr>");
}
out.print("</table>");
out.print("</body></html>");
} catch (Exception exc) {
exc.printStackTrace();
}
}
}
================================================================
================================================================
package mobile.mysql;
import java.io.*;
import javax.servlet.*;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.*;
import java.sql.*;
@WebServlet("/mobile.mysql/UpdateMobile")
public class UpdateMobile extends HttpServlet {
private static final long serialVersionUID = 5199742319711990244L;
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
response.setCharacterEncoding("UTF-8");
response.setContentType("text/html; charset=UTF-8");
PrintWriter out = response.getWriter();
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
ServletContext sc = this.getServletContext();
Class.forName(sc.getInitParameter("driver"));
conn = DriverManager.getConnection(sc.getInitParameter("url"),
"ID", "PASSWORD");
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT * FROM introduce" + " WHERE ID="
+ request.getParameter("ID"));
rs.next();
out.println("<html><head></head>");
out.println("<body><h1>테이블 정보</h1>");
out.println("<form action='UpdateMobile' method='post'>");
out.println("번호 : <input type='text' name='ID' value='"
+ request.getParameter("ID") + "' readonly><br>");
out.println("이름 : <input type='text' name='name' value='"
+ request.getParameter("name") + "'><br />");
out.println("나이 : <input type='text' name='age'" + " value='"
+ rs.getString("age") + "'><br/>");
out.println("전화 : <input type='text' name='tel'" + " value='"
+ rs.getString("tel") + "'><br/>");
out.println("성별 : <input type='text' name='gender'" + " value='"
+ rs.getString("gender") + "'><br/>");
out.println("주소 : <input type='text' name='addr'" + " value='"
+ rs.getString("addr") + "'><br/>");
out.println("<input type='submit' value='저장'>");
out.println("<input type='button' value='취소'"
+ " onclick='location.href=\"ResearchMobile\"'>");
out.println("</form>");
out.println("</body></html>");
} catch (Exception e) {
throw new ServletException(e);
} finally {
try {
if (rs != null)
rs.close();
} catch (Exception e) {
}
try {
if (stmt != null)
stmt.close();
} catch (Exception e) {
}
try {
if (conn != null)
conn.close();
} catch (Exception e) {
}
}
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
request.setCharacterEncoding("UTF-8");
Connection con = null;
PreparedStatement ps = null;
ServletContext sc = this.getServletContext();
String sql = "UPDATE introduce SET name=?,age=?,tel=?,gender=?,
addr=? WHERE ID=?";
try {
Class.forName(sc.getInitParameter("driver"));
con = DriverManager.getConnection(sc.getInitParameter("url"),
"ID", "PASSWORD");
ps = con.prepareStatement(sql);
ps.setString(1, request.getParameter("name"));
ps.setString(2, request.getParameter("age"));
ps.setString(3, request.getParameter("tel"));
ps.setString(4, request.getParameter("gender"));
ps.setString(5, request.getParameter("addr"));
ps.setInt(6, Integer.parseInt(request.getParameter("ID")));
ps.executeUpdate();
response.sendRedirect("ResearchMobile");
} catch (Exception exc) {
exc.printStackTrace();
} finally {
try {
if (ps != null)
ps.close();
} catch (Exception e) {
}
try {
if (con != null)
con.close();
} catch (Exception e) {
}
}
}
}
================================================================